FED-STD 1016
The fixed, stochastically-derived ''stochastic" codes aredescribed infection 3.3.
is described in section 3.4. Adaptive codes are described in section 3.5 and adaptive code gain is
described in section 3.6. Section 3.7 describes the Linear Prediction Filter and the Line Spectral
Parameters (LSPS) that adjust it. Section 3.8 shows transmission format, including bit assignments for
the transmitted information. Single bit error correction on some of the most sensitive bits is described
in section 3.9.
3.1.2 Postfiltering.
may be used to enhance the synthesized voice coming out of the
CELP Linear Prediction Filter.
3.1.3 Lowpass Filtering. Lowpass (i.e., reconstruction) filtering shall
be employed. A typical
lowpass filter has a 3
attenuation point at 3,800 Hz, less than 1
of passband ripple, and
minimum attenuations of 18
at 4,000 Hz and 46
above 4,400 Hz. In
certain applications, mild
highpass filtering (e.g., 175 Hz second-order Butterworth) may also be of
benefit.
3.2 Voice
3.2.1 Voice Input Filtering. The analog voice input bandpass should be essentially flat from 200
to 3,400 Hz. A typical input filter has 3
attenuation points at 100 and 3,800 Hz; less than 1
of
inband ripple; and minimum attenuations of 18
at 50 Hz, 18
at 4,000 Hz, and 46
above
4,400 Hz.
3.2.2 Analog-to-Digital Conversion. Analog-to-digital conversion shall use an 8 kHz
0.1 percent
sampling frequency and have a dynamic range of at least 12 bits.
3.2.3 Amplitude Scaling. To maintain proper receiver voice levels, analysis shall be based upon use
of input digitized voice whose peak values are -32,768 and +32,767.
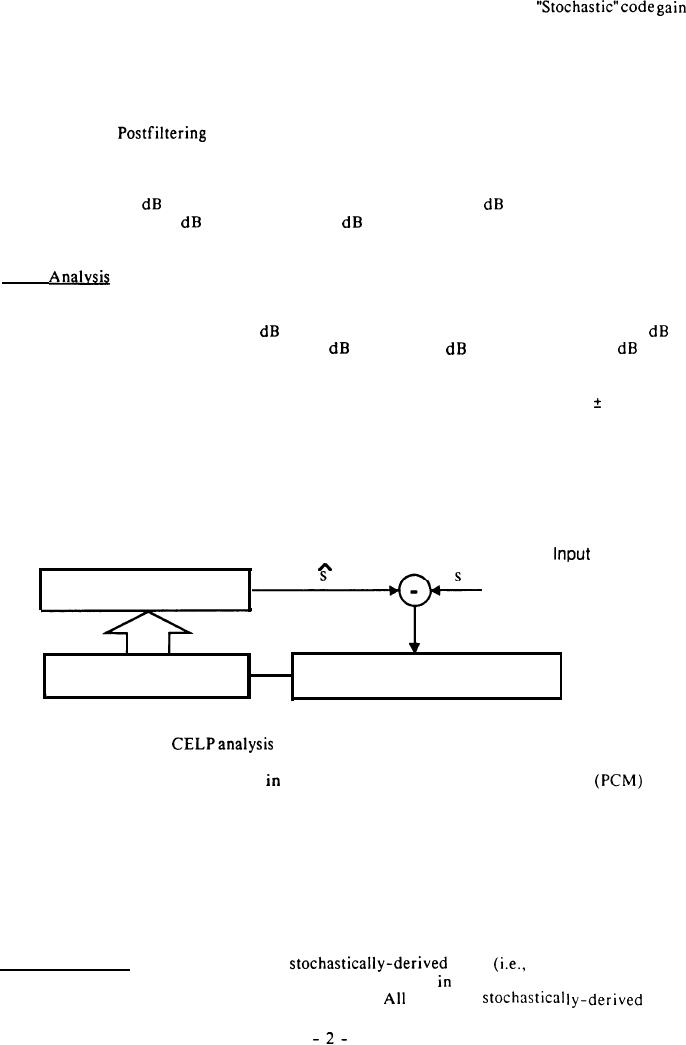
3 . 2 . 4 Analysis. As reflected in the following diagram, CELP is an analysis-by-synthesis type of
PCM
(8 kHz Sampling)
I
CELP Synthesizer
Perceptual Weighting Filter
Error Minimization
4
technique. The objective of
is to minimize the perceptual difference (i.e., find the best
match) between the actual digitized voice and the synthesized voice resulting from use of the
parameters to be transmitted. As shown
the diagram, linear Pulse Code Modulated
voice
sampled at 8 kHz is subtracted from the CELP synthesizer approximation and passed through a
perceptual weighting filter (see section 3.2.5). The synthesizer parameters to be transmitted are
adjusted for minimum perceptual error with respect to the actual input voice signal.
3.2.5 Perceptual Weighting Filter. It is recommended that a perceptual weighting filter be the
cascade of a linear predictive whitening filter and a bandwidth expanded linear predictive synthesis
filter. The bandwidth expanded linear predictive synthesis filter's poles are moved radially toward
the origin by a weighting factor, typically 0.8.
3.3 "Stochastic" Codes. There are 512 fixed,
codes
vectors). During voice
analysis, a code may be selected from a set smaller than 512
order to reduce computational
complexity (at the expense of voice reproduction quality).
512 fixed,
codes